Appearance
Model Predictive Path Integral (MPPI)
Problem Statement
MPPI addresses nonlinear trajectory tracking without local linearization by sampling control perturbations and weighting trajectories by cost. It is effective in regimes with nonconvex costs and uncertain dynamics.
Model and Formulation
For control sequence U, MPPI computes update:
$$ \Delta u_t = \frac{\sum_{k=1}^{K} \exp\left(-\frac{1}{\lambda}S_k\right)\epsilon_{k,t}}{\sum_{k=1}^{K} \exp\left(-\frac{1}{\lambda}S_k\right)} $$
where S_k is rollout cost and \epsilon_{k,t} is sampled perturbation at time t.
Algorithm Procedure
- Sample
Knoisy control sequences around nominal controls. - Roll out dynamics and compute trajectory costs.
- Compute importance-weighted control correction.
- Shift horizon and repeat at each control cycle.
Tuning Guidance
- Increase sample count
Kfor better solution quality. - Lower temperature
\lambdasharpens elite trajectory selection. - Match exploration covariance to expected disturbance magnitudes.
Failure Modes and Diagnostics
- Insufficient samples lead to high-variance control updates.
- Overly aggressive exploration destabilizes near-hover behavior.
- Large horizon with slow hardware can violate realtime deadlines.
Implementation and Execution
bash
python -m uav_sim.simulations.trajectory_tracking.mppiEvidence
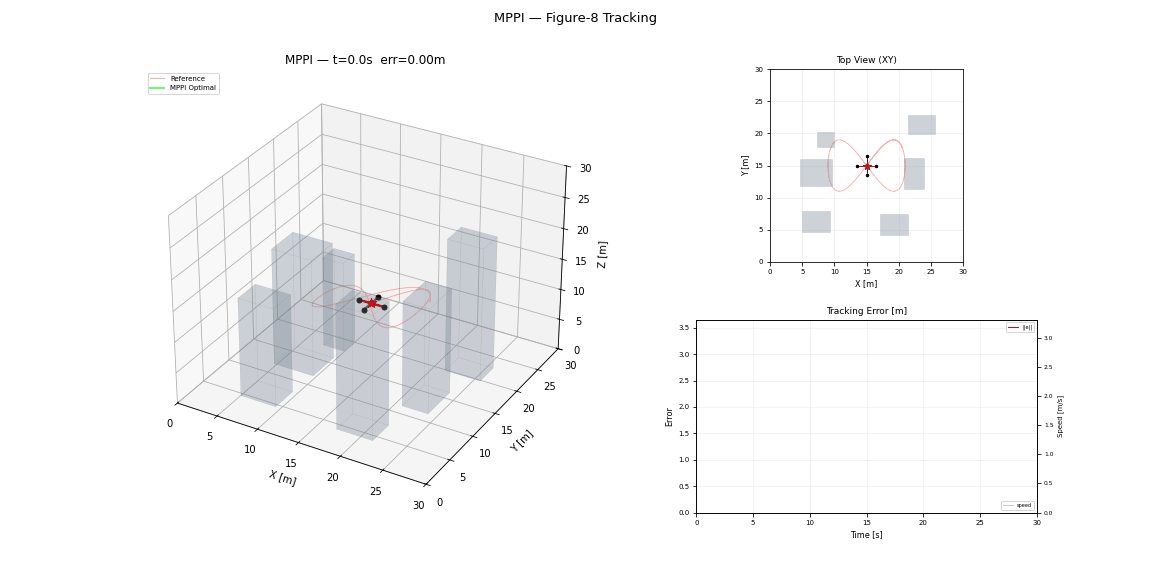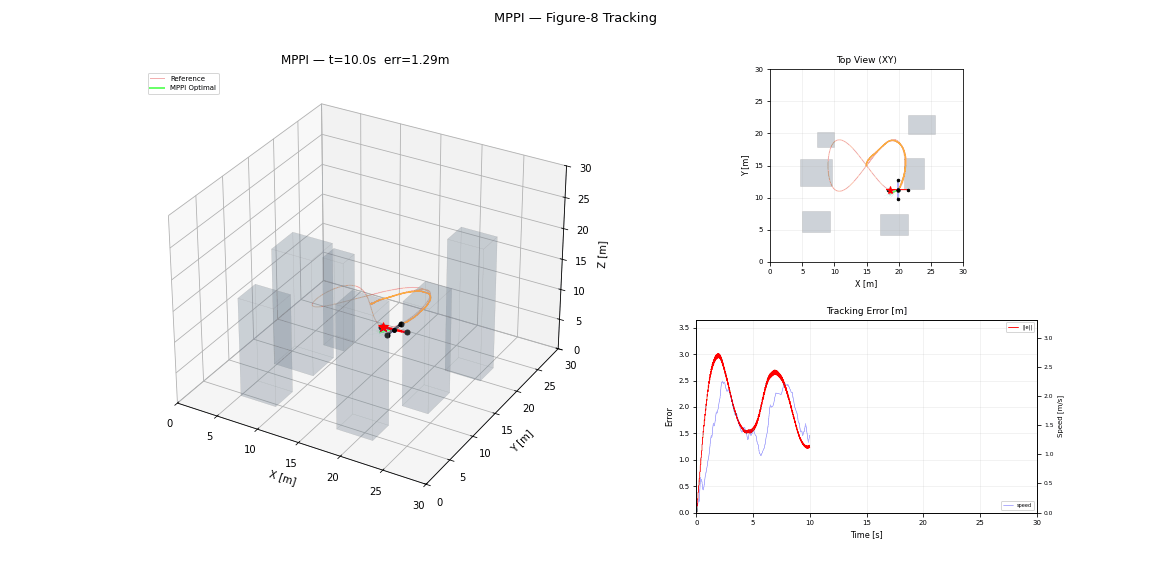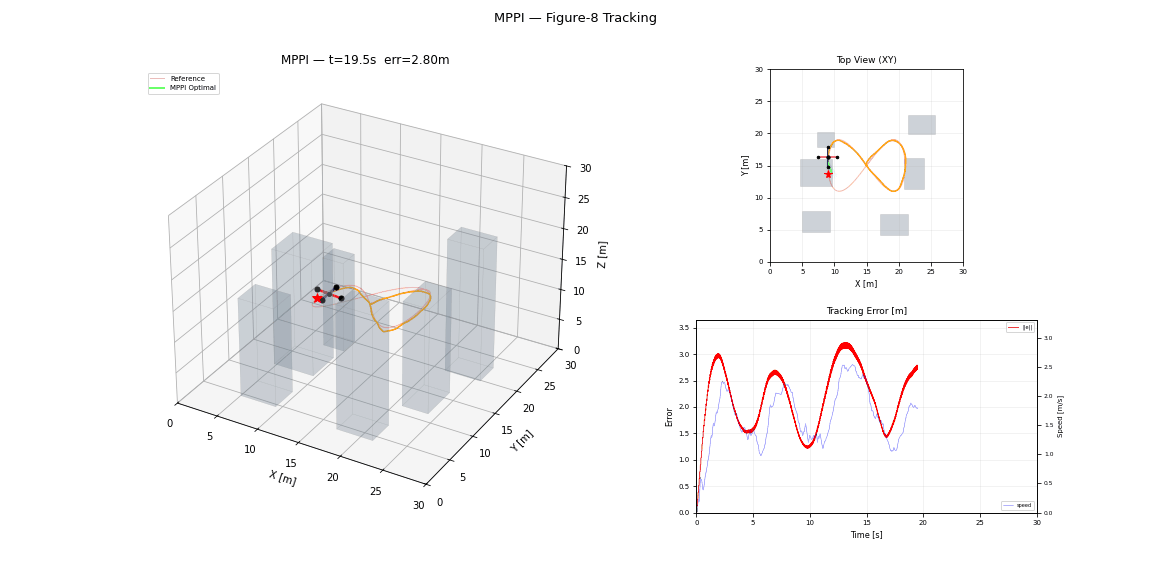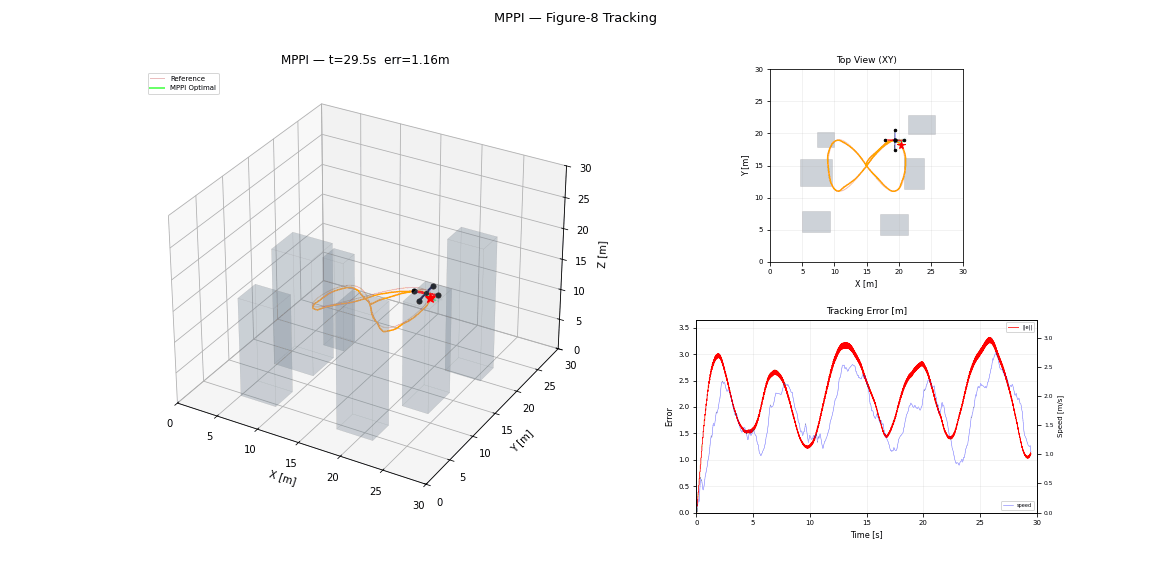
References
- Williams et al., Information Theoretic MPC for Model-Based Reinforcement Learning (2017)
- Theodorou et al., Policy Improvement with Path Integrals (2010)